2 传统RNN模型
学习目标¶
- 了解传统RNN的内部结构及计算公式.
- 掌握Pytorch中传统RNN工具的使用.
- 了解传统RNN的优势与缺点.
1 传统RNN的内部结构图¶
1.1 RNN结构分析¶
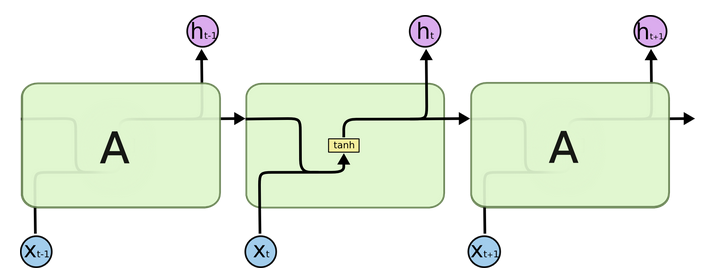
- 结构解释图:

-
内部结构分析:
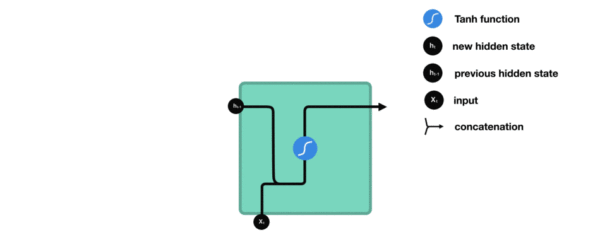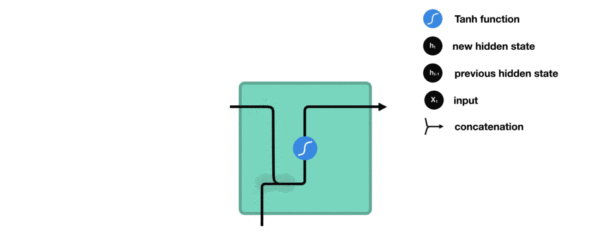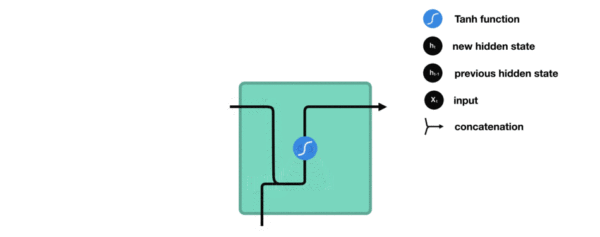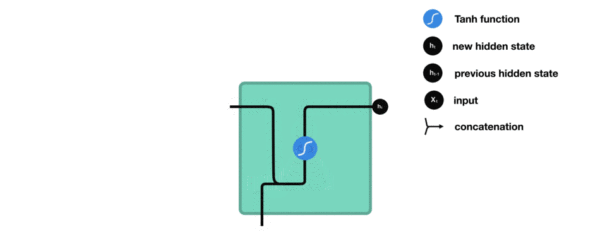
- 我们把目光集中在中间的方块部分, 它的输入有两部分, 分别是h(t-1)以及x(t), 代表上一时间步的隐层输出, 以及此时间步的输入, 它们进入RNN结构体后, 会"融合"到一起, 这种融合我们根据结构解释可知, 是将二者进行拼接, 形成新的张量[x(t), h(t-1)], 之后这个新的张量将通过一个全连接层(线性层), 该层使用tanh作为激活函数, 最终得到该时间步的输出h(t), 它将作为下一个时间步的输入和x(t+1)一起进入结构体. 以此类推.
-
内部结构过程演示:
-
根据结构分析得出内部计算公式: $$ h_t = tanh(W_t[X_t, h_{t-1}] + b_t) $$
-
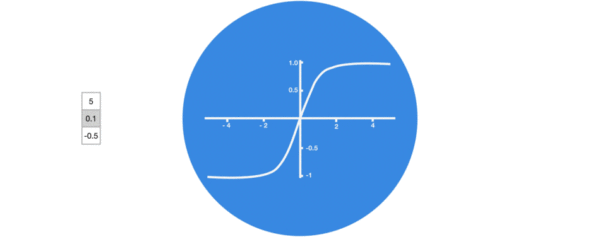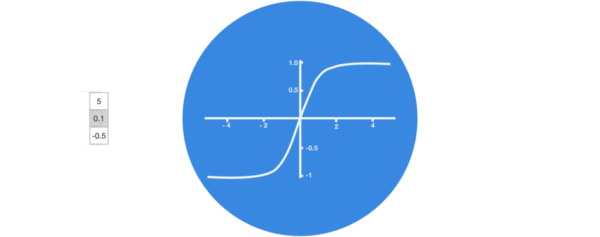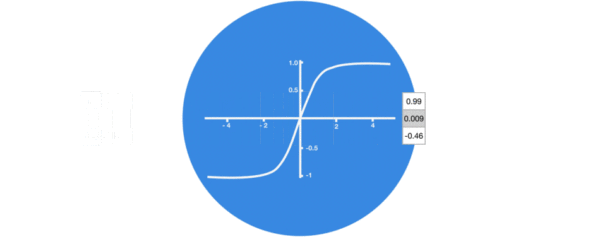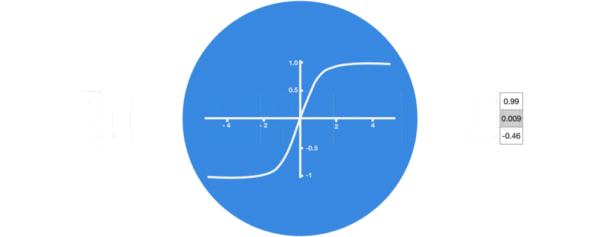
激活函数tanh的作用:
- 用于帮助调节流经网络的值, tanh函数将值压缩在-1和1之间.
1.2 使用Pytorch构建RNN模型¶
- 位置: 在torch.nn工具包之中, 通过torch.nn.RNN可调用
- nn.RNN使用示例1:
import torch
import torch.nn as nn
def dm_rnn_for_base():
'''
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
'''
rnn = nn.RNN(5, 6, 1) #A
'''
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
'''
input = torch.randn(1, 3, 5) #B
'''
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
'''
h0 = torch.randn(1, 3, 6) #C
# [1,3,5],[1,3,6] ---> [1,3,6],[1,3,6]
output, hn = rnn(input, h0)
print('output--->',output.shape, output)
print('hn--->',hn.shape, hn)
print('rnn模型--->', rnn)
# 程序运行效果如下:
output---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434],
[ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549],
[-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]],
grad_fn=<StackBackward0>)
hn---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434],
[ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549],
[-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]],
grad_fn=<StackBackward0>)
rnn模型---> RNN(5, 6)
- nn.RNN使用示例2
# 输入数据长度发生变化
def dm_rnn_for_sequencelen():
'''
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
'''
rnn = nn.RNN(5, 6, 1) #A
'''
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
'''
input = torch.randn(20, 3, 5) #B
'''
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
'''
h0 = torch.randn(1, 3, 6) #C
# [20,3,5],[1,3,6] --->[20,3,6],[1,3,6]
output, hn = rnn(input, h0) #
print('output--->', output.shape)
print('hn--->', hn.shape)
print('rnn模型--->', rnn)
# 程序运行效果如下:
output---> torch.Size([20, 3, 6])
hn---> torch.Size([1, 3, 6])
rnn模型---> RNN(5, 6)
- nn.RNN使用示例3
def dm_run_for_hiddennum():
'''
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
'''
rnn = nn.RNN(5, 6, 2) # A 隐藏层个数从1-->2 下面程序需要修改的地方?
'''
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
'''
input = torch.randn(1, 3, 5) # B
'''
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
'''
h0 = torch.randn(2, 3, 6) # C
output, hn = rnn(input, h0) #
print('output-->', output.shape, output)
print('hn-->', hn.shape, hn)
print('rnn模型--->', rnn) # nn模型---> RNN(5, 6, num_layers=11)
# 结论:若只有一个隐藏次 output输出结果等于hn
# 结论:如果有2个隐藏层,output的输出结果有2个,hn等于最后一个隐藏层
# 程序运行效果如下:
output--> torch.Size([1, 3, 6]) tensor([[[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244],
[ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437],
[ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]],
grad_fn=<StackBackward0>)
hn--> torch.Size([2, 3, 6]) tensor([[[ 0.4862, 0.6872, -0.0437, -0.7826, -0.7136, -0.5715],
[ 0.8942, 0.4524, -0.1695, -0.5536, -0.4367, -0.3353],
[ 0.5592, 0.0444, -0.8384, -0.5193, 0.7049, -0.0453]],
[[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244],
[ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437],
[ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]],
grad_fn=<StackBackward0>)
rnn模型---> RNN(5, 6, num_layers=2)
1.3 传统RNN优缺点¶
1 传统RNN的优势¶
- 由于内部结构简单, 对计算资源要求低, 相比之后我们要学习的RNN变体:LSTM和GRU模型参数总量少了很多, 在短序列任务上性能和效果都表现优异.
2 传统RNN的缺点¶
- 传统RNN在解决长序列之间的关联时, 通过实践,证明经典RNN表现很差, 原因是在进行反向传播的时候, 过长的序列导致梯度的计算异常, 发生梯度消失或爆炸.
3 梯度消失或爆炸介绍¶
根据反向传播算法和链式法则, 梯度的计算可以简化为以下公式
D_n=\sigma^{\prime}(z_1)w_1\cdot\sigma^{\prime}(z_2)w_2\cdot_{\cdots}\cdot\sigma^{\prime}(z_n)w_n
-
其中sigmoid的导数值域是固定的, 在[0, 0.25]之间, 而一旦公式中的w也小于1, 那么通过这样的公式连乘后, 最终的梯度就会变得非常非常小, 这种现象称作梯度消失. 反之, 如果我们人为的增大w的值, 使其大于1, 那么连乘够就可能造成梯度过大, 称作梯度爆炸.
-
梯度消失或爆炸的危害:
- 如果在训练过程中发生了梯度消失,权重无法被更新,最终导致训练失败; 梯度爆炸所带来的梯度过大,大幅度更新网络参数,在极端情况下,结果会溢出(NaN值).
2 小结¶
-
学习了传统RNN的结构并进行了分析;
- 它的输入有两部分, 分别是h(t-1)以及x(t), 代表上一时间步的隐层输出, 以及此时间步的输入, 它们进入RNN结构体后, 会"融合"到一起, 这种融合我们根据结构解释可知, 是将二者进行拼接, 形成新的张量[x(t), h(t-1)], 之后这个新的张量将通过一个全连接层(线性层), 该层使用tanh作为激活函数, 最终得到该时间步的输出h(t), 它将作为下一个时间步的输入和x(t+1)一起进入结构体. 以此类推.
-
根据结构分析得出了传统RNN的计算公式.
-
学习了激活函数tanh的作用:
- 用于帮助调节流经网络的值, tanh函数将值压缩在-1和1之间.
-
学习了Pytorch中传统RNN工具的使用:
- 位置: 在torch.nn工具包之中, 通过torch.nn.RNN可调用.
-
nn.RNN类初始化主要参数解释:
- input_size: 输入张量x中特征维度的大小.
- hidden_size: 隐层张量h中特征维度的大小.
- num_layers: 隐含层的数量.
- nonlinearity: 激活函数的选择, 默认是tanh.
-
nn.RNN类实例化对象主要参数解释:
- input: 输入张量x.
- h0: 初始化的隐层张量h.
-
实现了nn.RNN的使用示例, 获得RNN的真实返回结果样式.
-
学习了传统RNN的优势:
- 由于内部结构简单, 对计算资源要求低, 相比之后我们要学习的RNN变体:LSTM和GRU模型参数总量少了很多, 在短序列任务上性能和效果都表现优异.
-
学习了传统RNN的缺点:
- 传统RNN在解决长序列之间的关联时, 通过实践,证明经典RNN表现很差, 原因是在进行反向传播的时候, 过长的序列导致梯度的计算异常, 发生梯度消失或爆炸.
-
学习了什么是梯度消失或爆炸:
- 根据反向传播算法和链式法则, 得到梯度的计算的简化公式:其中sigmoid的导数值域是固定的, 在[0, 0.25]之间, 而一旦公式中的w也小于1, 那么通过这样的公式连乘后, 最终的梯度就会变得非常非常小, 这种现象称作梯度消失. 反之, 如果我们人为的增大w的值, 使其大于1, 那么连乘够就可能造成梯度过大, 称作梯度爆炸.
-
梯度消失或爆炸的危害:
- 如果在训练过程中发生了梯度消失,权重无法被更新,最终导致训练失败; 梯度爆炸所带来的梯度过大,大幅度更新网络参数,在极端情况下,结果会溢出(NaN值).